Sentinel
Real-time account-takeover risk engine
Model card
xgboost won on PR-AUC. It was scored on a temporal hold-out, meaning we train on the earliest events and test on the latest, never a random shuffle that would let the model peek at the future. That test set is 58,031 events at 3.95% ATO. Scores are isotonic-calibrated, and every number below comes from that calibrated test set.
Precision–Recall
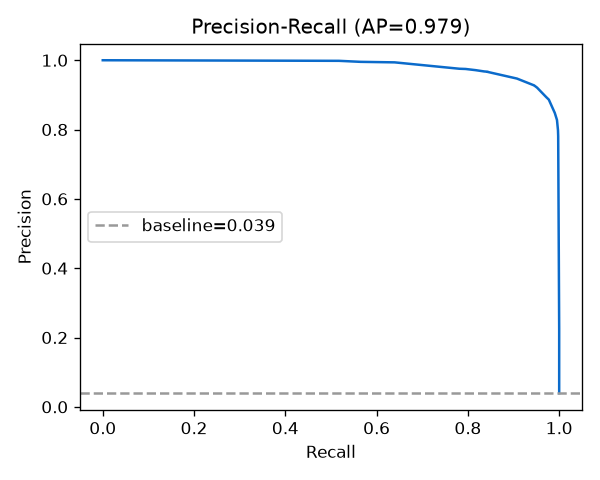
At 3% prevalence this is the curve that matters. It sits far above the baseline.
Calibration
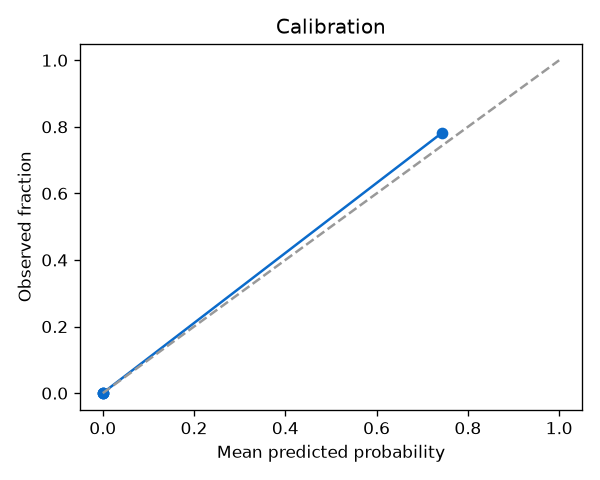
Isotonic-calibrated scores track how often ATO actually happens, so a 0.8 means about 80%.
Feature importance
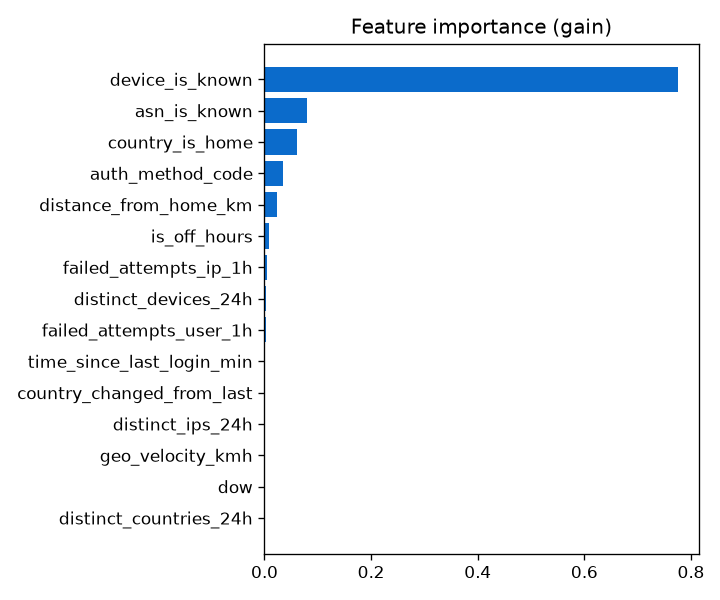
Velocity, device and network novelty, and failed-attempt counts do most of the work.
Score separation
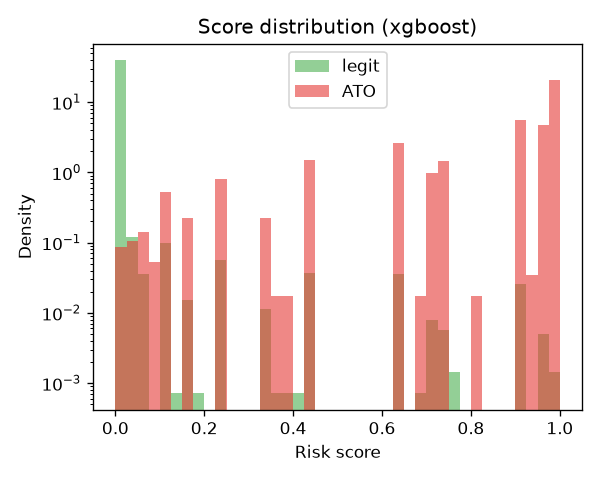
Legit vs ATO scores on a log scale. Where they overlap is error nothing can fix.